

안녕하세요. 오늘은 자바스크립트(JavaScript)로 웹 스크래핑(Web Scraping) 하는 방법에 대해 알아볼 거예요. 웹 스크래핑이란 웹 페이지에 있는 정보를 추출하는 과정이에요. 웹페이지는 HTML로 작성되어 있는데 웹 스크래핑을 통해 HTML 코드에서 우리가 원하는 정보를 찾아낼 수 있답니다.
웹 스크래핑은 서버 사이드 언어를 사용해서 수행하는 것이 일반적이에요. 하지만 프로그래밍에 필요한 소프트웨어 설치와 설정 과정이 복잡하기 때문에 오직 인터넷 브라우저만 있으면 바로 수행할 수 있는 자바스크립트로 알아보도록 할게요.
1. 아래와 같이 메뉴로 이동하거나, F12 키를 눌러서 개발자 모드를 활성화합니다.
2. 개발자 모드에서 아래 빨간 네모칸의 콘솔 모드 탭을 선택합니다.
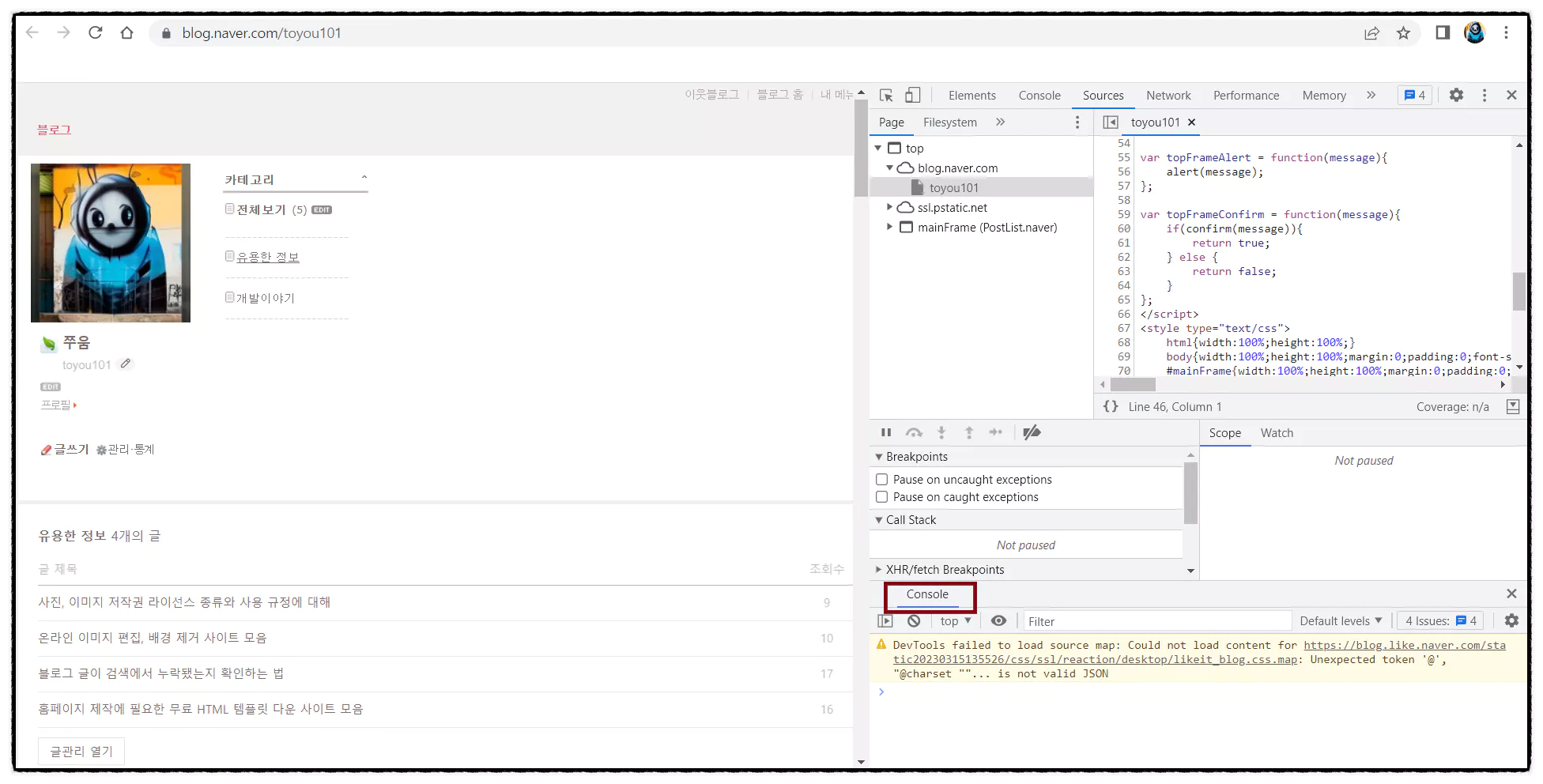
콘솔 창만 띄우면 자바스크립트 실행할 준비가 다 끝난 거예요! 이제 fetch를 사용해서 간단하게 호출해 보겠습니다. 예제로 저의 네이버 블로그 게시글 정보를 가져오는 코드를 만들어볼게요.
* javaScript의 fetch는 네트워크 요청을 보내는 기능을 제공합니다. 이 기능은 브라우저 api로서 서버와 데이터를 주고받을 수 있게 해 주는데, 일반적으로 json 데이터를 받아올 때 사용됩니다. 위의 예제는 블로그의 rss 피드 정보를 xml 형식으로 데이터를 반환하기 때문에 text로 데이터를 받은 후 xml 데이터를 파싱 하여 원하는 정보를 추출하겠습니다.
fetch("https://rss.blog.naver.com/toyou101")
.then((response) => response.text())
.then((data) => console.log(data))
실행 결과 ▼
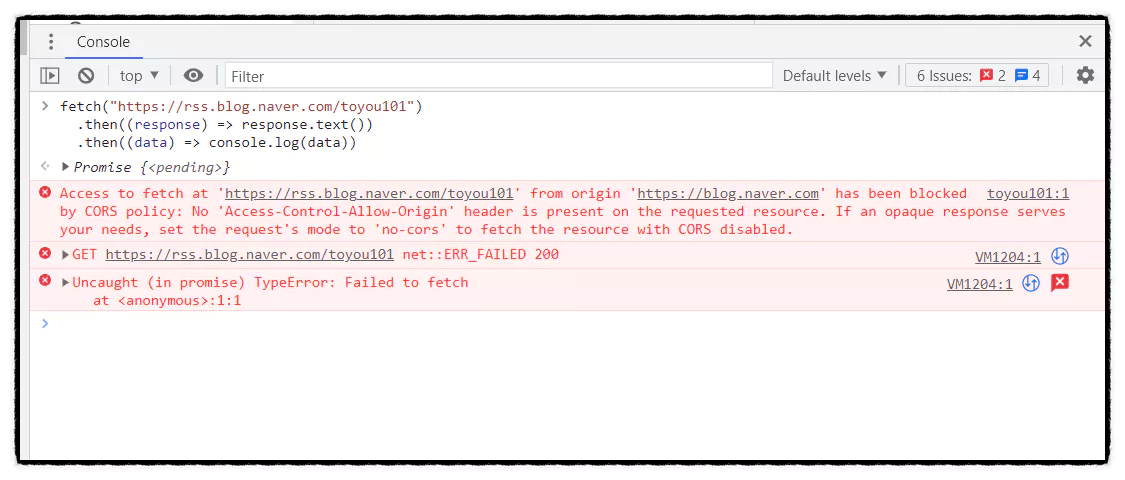
동일한 도메인이 아닌 다른 도메인으로 접근 시 CORS 정책에 의해 차단되었다는 에러 메시지가 나왔습니다. CORS는 웹 브라우저에서 보안 상의 이유로, 서로 다른 도메인(Origin) 간의 자원(Resource)에 접근하는 것을 제한하는 보안 정책이에요. 쉽게 말해서 rss.blog.naver에 있는 자원을 가져가려면 rss.blog.nave에서 요청해야 한다는 거죠. 이 정책은 브라우저에서 보안상의 이유로 적용되는 것이며, 서버와 서버 간의 통신에서는 적용되지 않습니다. 그렇다면? 프록시 서버를 사용해서 우회할 수 있습니다!
cors-anywhere.herokuapp 바로가기
CORS를 우회하기 위한 프록시 서버로 해당 url에 접속하여 데모 서버 요청 버튼을 클릭합니다.

간단하게 프록시 서버가 활성화됐네요. 그럼 이제 아래와 같이 요청 url을 붙여주고 다시 한번 실행해 보겠습니다. "http://cors-anywhere.herokuapp.com/{요청 url}"
fetch("https://cors-anywhere.herokuapp.com/https://rss.blog.naver.com/toyou101")
.then((response) => response.text())
.then((data) => console.log(data))
실행 결과 ▼
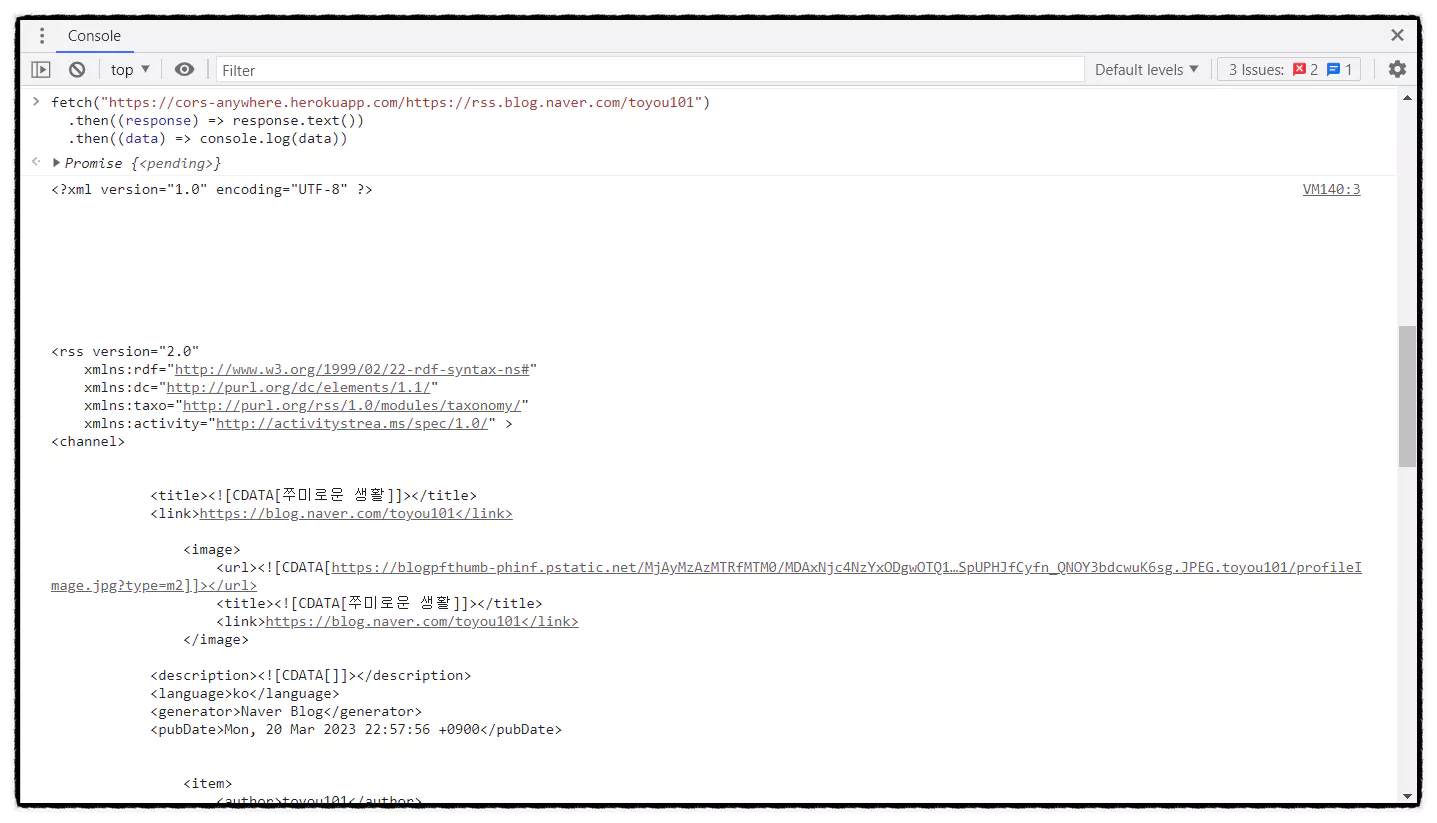
이제야 저의 블로그 게시글 정보를 가져왔네요. 정상적으로 데이터 받은 걸 확인했으니 xml 형식을 파싱 하여 원하는 데이터만 출력을 해볼게요. 그리고 더 쉽게 호출하기 위해 ID를 입력받는 function을 따로 만들고 호출할 수 있도록 하겠습니다.
//ID를 입력받아 해당 블로그의 게시글 목록을 출력
async function fetchRSSFeed(id) {
const proxyUrl = 'https://cors-anywhere.herokuapp.com/'
const feedUrl = ` https://rss.blog.naver.com/$ {id}.xml`;
// 프록시를 통해 RSS 피드 정보 조회
const response = await fetch(proxyUrl + feedUrl);
const str = await response.text();
const data = new window.DOMParser().parseFromString(str, 'text/xml');
// 피드 내의 모든 item 태그를 선택
const items = data.querySelectorAll('item');
//가져온 item태그의 title을 모두 추출
const titles = Array.from(items).map(item => item.querySelector('title').textContent);
// 가져온 title을 출력
var seq = 0 ;
for (const title of titles) {
seq++;
console.log(seq+'.' +' 제목: '+title);
}
}
function이 만들어졌으니 이제 콘솔 창에 위 코드를 입력 후 fetchRSSFeed('블로그 ID')를 호출해 볼게요.
fetchRSSFeed('toyou101') 실행 결과 ▼
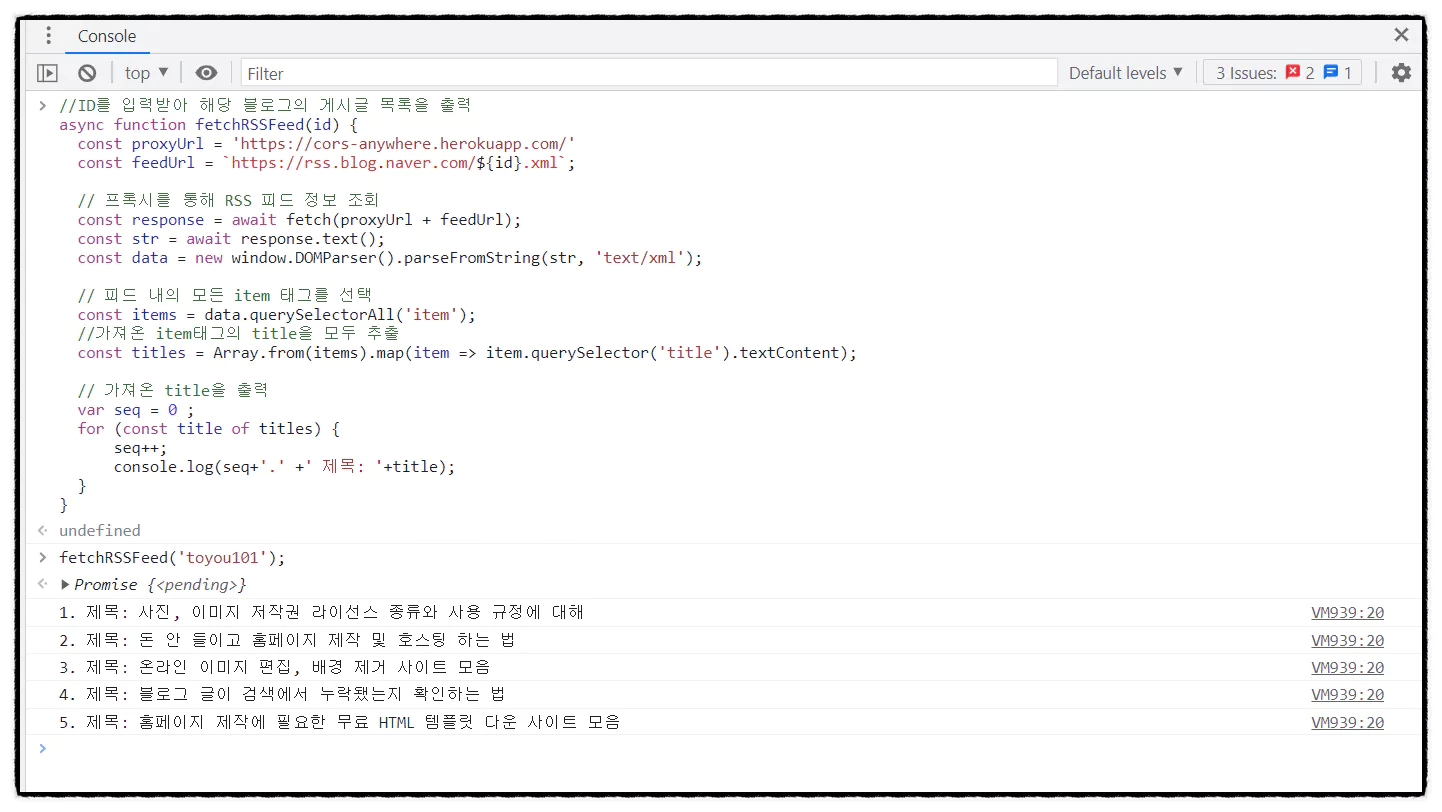
이제 제가 올린 게시글이 전부 목록에 나왔네요. 저는 블로그의 게시글 제목만 가져왔지만 피드 정보에는 제목뿐만 아니라 작성일, 내용(일부), 게시글의 url도 포함되어 있습니다.
자! 오늘은 이렇게 자바스크립트를 이용해서 블로그를 조회하는 웹 스크래핑 코드를 만들었는데요. 블로그뿐만 아니라 검색 결과, 날씨, 주식 등 다양한 웹페이지의 정보를 가져올 수 있습니다. 웹 스크래핑에 대해 간단하게 알아보았으니 이제 여러분도 웹페이지에서 원하는 정보를 가져올 수 있을 거예요. 웹 스크래핑을 활용하면 다양한 정보를 수집하고, 분석할 수 있습니다!
주의: 웹 페이지에 포함된 이미지, 텍스트, 동영상 등의 자료는 해당 페이지의 소유자에게 저작권이 있을 수 있습니다. 따라서, 이러한 자료를 스크래핑하거나 무단으로 사용하는 것은 저작권 침해로 간주될 수 있습니다. 또한 웹 스크래핑의 과도 한 사용, 대량의 자료를 수집하는 경우, 서버의 부하를 높일 수 있어 검색 서비스 제한에 걸릴 수도 있습니다. 법적 또는 이용 약관 상의 문제를 피하려면 공식 API를 사용하는 것이 좋습니다. - 끝 -
